


DNA là phân tử mang thông tin di truyền quy định mọi hoạt động sống (sinh trưởng, phát triển và sinh sản) của các sinh vật và nhiều loài virus. Đây là từ viết tắt thuật ngữ tiếng Anh deoxyribonucleic acid (/diːˈɒksɪˌraɪboʊnjuːˌkliːɪk,
Hai mạch DNA này được gọi là các polynucleotide vì thành phần của chúng bao gồm các đơn phân nucleotide. Mỗi nucleotide được cấu tạo từ một trong bốn loại nucleobase chứa nitơ—hoặc là cytosine (C), guanine (G), adenine (A), hay thymine (T)—liên kết với đường deoxyribose và một nhóm phosphat. Các nucleotide liên kết với nhau thành một mạch DNA bằng liên kết phosphodieste (liên kết cộng hóa trị) giữa phân tử đường của nucleotide với nhóm phosphat của nucleotide tiếp theo, tạo thành "khung xương sống" đường-phosphat luân phiên vững chắc.
Những base nitơ giữa hai mạch đơn polynucleotide liên kết với nhau theo nguyên tắc bổ sung (A liên kết với T, và C liên kết với G) thông qua các mối liên kết hydro để tạo nên chuỗi DNA mạch kép. Tổng số lượng cặp base liên quan tới DNA trên Trái Đất ước tính bằng 5,0 x 1037, và nặng khoảng 50 tỷ tấn. Để so sánh, tổng khối lượng của sinh quyển xấp xỉ bằng 4 nghìn tỷ tấn carbon.
DNA lưu trữ thông tin sinh học, các mã di truyền đến các thế hệ tiếp theo và để chỉ dẫn cho quá trình sinh tổng hợp protein. Mạch đơn DNA có liên kết hóa học vững chắc chống lại sự phân cắt, và hai mạch đơn của chuỗi xoắn kép lưu trữ thông tin sinh học như nhau. Thông tin này được sao chép nhờ sự phân tách hai mạch đơn. Một tỷ lệ đáng kể DNA (hơn 98% ở người) là các đoạn DNA không mã hóa (non-coding), nghĩa là những vùng này không giữ vai trò mạch khuôn để xác định trình tự protein thông qua các quá trình phiên mã, dịch mã.
Hai mạch DNA chạy song song theo hai hướng ngược nhau. Gắn với mỗi phân tử đường là một trong bốn loại nucleobase (hay các base). Thông tin di truyền được mã hóa bởi trình tự của bốn nucleobase gắn trên mỗi mạch đơn. Những mạch RNA được tổng hợp từ những khuôn mẫu DNA trong quá trình phiên mã. Và dưới sự chỉ dẫn của mã di truyền, phân tử RNA tiếp tục được diễn dịch để xác định trình tự các amino acid ở cấu trúc protein trong quá trình dịch mã.
DNA ở tế bào nhân thực (động vật, thực vật, nấm và nguyên sinh vật) được lưu trữ bên trong nhân tế bào và một số bào quan, như ty thể hoặc lục lạp. Ngược lại, ở sinh vật nhân sơ (vi khuẩn và vi khuẩn cổ), do không có nhân tế bào, DNA nằm trong tế bào chất. Bên trong tế bào, DNA tổ chức thành những cấu trúc dài gọi là nhiễm sắc thể (chromosome). Trong giai đoạn phân bào các nhiễm sắc thể hình thành được nhân đôi bằng cơ chế nhân đôi DNA, mang lại cho mỗi tế bào có một bộ nhiễm sắc thể hoàn chỉnh như nhau. Ở nhiễm sắc thể sinh vật nhân thực, những protein chất nhiễm sắc (chromatin) như histone giúp thắt chặt và tổ chức cấu trúc DNA. Chính cấu trúc thắt chặt này sẽ quản lý sự tương tác giữa DNA với các protein khác, quy định vùng nào của DNA sẽ được phiên mã.
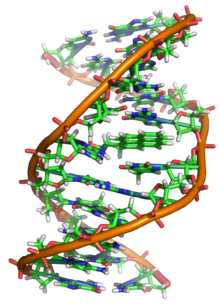
Friedrich Miescher đã cô lập được DNA lần đầu tiên vào năm 1869. Francis Crick và James Watson nhận ra cấu trúc phân tử chuỗi xoắn kép của nó vào năm 1953, dựa trên mô hình xây dựng từ dữ liệu thu thập qua ảnh chụp nhiễu xạ tia X do Rosalind Franklin thực hiện. DNA trở thành một công cụ phân tử giúp các nhà nghiên cứu khám phá các lý thuyết và định luật vật lý sinh học, như định lý ergodic và lý thuyết đàn hồi. Những tính chất vật liệu độc đáo của DNA biến nó trở thành phân tử hữu ích đối với các nhà khoa học vật liệu quan tâm trong lĩnh vực chế tạo vật liệu cỡ micro và nano, như trong công nghệ nano DNA. Các tiến bộ trong lĩnh vực này bao gồm phương pháp origami DNA và vật liệu lai dựa trên DNA.
Cấu trúc


DNA là một polymer dài cấu tạo bởi các đơn phân nucleotide lặp lại. Cấu trúc DNA của mọi loài là động không phải là tĩnh. Hai mạch polynucleotide liên kết với nhau bằng liên kết hydro, xoắn đều quanh một trục tưởng tượng theo chiều từ trái sang phải (xoắn phải), mỗi chu kỳ xoắn dài 34 ångström (3,4 nm) và có bán kính 10 ångström (1,0 nm). Theo một nghiên cứu, khi đo đạc trong một dung dịch, chuỗi phân tử DNA rộng 22–26 Å (2.2–2.6 nm, và một đơn phân nucleotide dài 3,3 Å (0,33 nm). Dù cho mỗi đơn vị lặp lại có kích thước rất nhỏ, polymer DNA vẫn là những phân tử rất lớn chứa hàng triệu nucleotide. Ví dụ, DNA trong nhiễm sắc thể lớn nhất ở người, nhiễm sắc thể số 1, chứa xấp xỉ 220 triệu cặp base và dài đến 85 mm nếu được duỗi thẳng.


DNA thường không là một chuỗi đơn lẻ, mà thay vào đó là cặp chuỗi liên kết chặt chẽ với nhau. Hai mạch dài này quấn gắn kết với nhau. Một nucleobase liên kết với một phân tử đường tạo thành cấu trúc gọi là nucleoside, và một base liên kết với một phân tử đường và một hoặc nhiều nhóm phosphat gọi là nucleotide (nucleotide trong DNA và RNA là loại nucleotide chỉ mang một nhóm phosphat). Mạch polymer chứa nhiều nucleotide liên kết với nhau (như trong DNA) được gọi là polynucleotide.
Khung xương chính của mạch DNA tạo nên từ các nhóm phosphat và phân tử đường xen kẽ nhau. Phân tử đường trong DNA là 2-deoxyribose, là đường pentose (5 carbon). Các phân tử đường liên kết với các nhóm phosphat tạo thành liên kết phosphodieste giữa nguyên tử carbon thứ 3 với nguyên tử carbon thứ 5 trên hai mạch vòng của hai phân tử đường liền kề. Liên kết bất đối xứng này cho phép xác định hướng chạy của mạch đơn DNA. Xem xét gần hơn trên một chuỗi xoắn kép, người ta nhận thấy các nucleotide hướng theo một chiều trên một mạch và theo chiều ngược lại trên mạch kia, gọi là: hai mạch hướng ngược chiều nhau hay đối song song (antiparallel). Các đầu không đối xứng kết thúc của chuỗi DNA là đầu 5′ (năm phẩy) và đầu 3′ (ba phẩy), với đầu 5′ kết thúc bởi nhóm phosphat và đầu 3′ kết thúc bởi nhóm hydroxyl (OH). Sự khác nhau chủ yếu giữa DNA và RNA là ở phân tử đường, với đường 2-deoxyribose trong DNA được thay thế bởi đường ribose trong RNA.
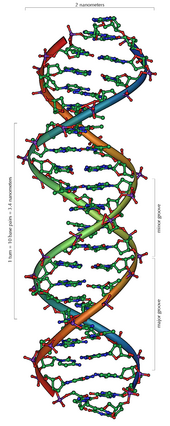
Chuỗi xoắn kép DNA được ổn định bởi hai lực liên kết chính: liên kết hydro giữa các nucleotide của hai mạch và tương tác xếp chồng (base-stacking) giữa các base nitơ. Bốn base trong DNA là adenine (A), cytosine (C, ở Việt Nam còn viết là xitôzin, viết tắt X), guanine (G) và thymine (T). Bốn base này gắn với nhóm đường/phosphat để tạo thành nucleotide hoàn chỉnh, như adenosine monophosphate. Adenine ghép cặp với thymine và guanine ghép cặp với cytosine, ký hiệu bằng các cặp base A-T và G-C.

Phân loại nucleobase
Nucleobase được phân thành hai loại: purine, gồm adenine (A) và guanine (G), là hợp chất dị vòng 5 và 6 cạnh hợp nhất; và pyrimidine, gồm cytosine (C) và thymine (T), có vòng 6 cạnh C và T.Nucleobase pyrimidine thứ năm là uracil (U), thường thay thế thymine (T) trong RNA và khác với thymine là thiếu đi nhóm methyl (–CH3) trên vòng. Ngoài RNA và DNA, một số lượng lớn chất tương tự acid nucleic nhân tạo được tạo ra để nghiên cứu các tính chất của acid nucleic, hoặc sử dụng trong công nghệ sinh học.
Uracil thường không có ở DNA, nó chỉ xuất hiện như một sản phẩm phân tách của cytosine. Tuy nhiên, ở một số thực khuẩn thể như: thực khuẩn thể ở Bacillus subtilis PBS1 và PBS2 và thực khuẩn Yersinia piR1-37, thì thymine được thay bằng uracil. Một thực khuẩn thể khác - thể Staphylococcal S6 - được phát hiện với bộ gene mà thymine thay bằng uracil.
Base J (beta-d-glucopyranosyloxymethyluracil), một dạng tinh chỉnh của uracil, cũng xuất hiện ở một số sinh vật: trùng roi Diplonema và Euglena, và mọi nhóm Kinetoplastida. Sinh tổng hợp base J diễn ra theo hai bước: bước thứ nhất một thymidine xác định trong DNA được biến đổi thành hydroxymethyldeoxyuridine (HOMedU); bước thứ hai HOMedU được glycosyl hóa thành base J. Các nhà khoa học cũng khám phá ra những protein được tổng hợp từ base này. Những protein này dường như có họ hàng xa với gene gây ung thư (oncogene) Tet1 mà tham gia vào quá trình phát sinh bệnh bạch cầu myeloid cấp tính. Base J cũng đóng vai trò làm tín hiệu kết thúc cho enzyme RNA polymerase II.
Rãnh DNA
Hai mạch đơn xoắn đôi vào nhau tạo thành bộ khung cho DNA. Ở chuỗi xoắn kép này có thể xuất hiện những khoảng trống nằm cách nhau giữa hai mạch gọi là các rãnh (groove). Những rãnh này nằm liền kề với các cặp base và có thể hình thành một điểm bám (binding site). Vì hai mạch đơn không đối xứng nhau nên dẫn đến các rãnh có kích thước không đều, trong đó rãnh lớn (major groove) rộng 22 Å và rãnh nhỏ (minor groove) rộng 12 Å. Độ rộng của rãnh giúp cho các cạnh của base trở nên dễ tiếp cận hơn trong rãnh lớn so với rãnh nhỏ. Kết quả là, các protein của các nhân tố phiên mã mà liên kết với những đoạn trình tự cụ thể trong chuỗi xoắn kép DNA thường thực hiện bằng việc tiếp xúc với các cạnh của các base ở rãnh lớn. Tình huống này thay đổi đa dạng tùy theo hình dáng bất thường của DNA bên trong tế bào (xem ở dưới), nhưng các rãnh lớn và rãnh nhỏ luôn luôn được đặt tên để phản ánh sự khác nhau về kích thước đo được nếu DNA vặn xoắn trở về dạng B thường gặp.
Cặp base
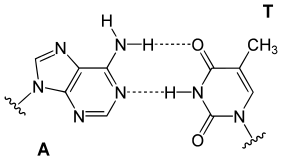
Trong chuỗi xoắn kép DNA, mỗi loại nucleobase trên một mạch chỉ liên kết với một loại nucleobase trên mạch kia. Đây được gọi là nguyên tắc bắt cặp bổ sung. Ở đây, purine tạo liên kết hydro với pyrimidine, trong đó adenine chỉ liên kết với thymine bằng hai liên kết hydro, và cytosine chỉ liên kết với guanine bằng ba liên kết hydro. Sự sắp xếp giữa hai nucleotide liên kết với nhau qua chuỗi xoắn kép gọi là cặp base Watson-Crick. DNA có cặp nhiều G-C ổn định hơn DNA có ít cặp G-C. Cặp base Hoogsteen là một dạng biến thể hiếm gặp của việc bắt cặp bổ sung. Vì liên kết hydro không phải là liên kết cộng hóa trị, nên có thể bị đứt gãy và liên kết lại tương đối dễ dàng. Hai mạch của DNA trong chuỗi xoắn kép do vậy có thể tách rời nhau bằng lực cơ học hoặc bằng nhiệt độ cao, giống như khóa kéo. Hệ quả của nguyên tắc bắt cặp bổ sung này là mọi thông tin trong trình tự chuỗi xoắn kép DNA được lặp lại ở mỗi mạch, và có vai trò quan trọng trong quá trình nhân đôi DNA. Sự tương tác đặc hiệu và có thể hồi phục này giữa các cặp bazơ bổ sung là tối quan trọng đối với mọi chức năng của DNA trong sinh vật.

|
|
Hình dưới, cặp base A-T có hai liên kết hydro. Liên kết hydro không phải là liên kết cộng hóa trị được thể hiện bằng gạch ngang.
ssDNA so với dsDNA
Như đã nói ở trên, hầu hết phân tử DNA bao gồm hai mạch polymer, liên kết thành dạng xoắn kép bằng liên kết hydro không phải là liên kết cộng hóa trị; cấu trúc mạch kép (dsDNA - double stranded DNA) được duy trì chủ yếu bởi tương tác xếp chồng base, mạnh nhất là xếp chồng G,C. Hai mạch có thể tách rời—quá trình gọi là sự nóng chảy—tạo thành hai phân tử DNA mạch đơn (ssDNA - single-stranded DNA). Sự tách rời xảy ra ở nhiệt độ cao, độ mặn thấp và độ pH cao (độ pH thấp cũng làm tách DNA, nhưng vì DNA không ổn định do quá trình khử purine, do đó độ pH thấp ít khi được sử dụng).
Sự ổn định của dạng mạch kép dsDNA không chỉ phụ thuộc vào thành phần G-C (tỷ lệ % cặp base G-C) mà còn phụ thuộc vào trình tự các base và độ dài (phân tử càng dài thì càng ổn định). Độ ổn định được đo bằng nhiều cách khác nhau; cách phổ biến là đưa phân tử đạt tới nhiệt độ nóng chảy (còn gọi là giá trị Tm), đó là nhiệt độ mà tại đấy khoảng 50% số phân tử mạch kép biến đổi thành phân tử mạch đơn; nhiệt độ nóng chảy phụ thuộc vào cường độ ion và nồng độ DNA. Do vậy, cả tỷ lệ phần trăm số cặp base G-C và chiều dài tổng thể của chuỗi xoắn kép DNA xác định nên cường độ liên kết giữa hai mạch DNA. Những chuỗi xoắn kép DNA dài có nhiều cặp G-C có tương tác giữa hai mạch mạnh hơn so với những chuỗi xoắn kép ngắn với thành phần nhiều A-T. Trong hoạt động sinh học, có những phần của chuỗi xoắn kép DNA dễ dàng tách rời, ví dụ như Pribnow box TATAAT ở một số vùng khởi động (promoter), có xu hướng chứa nhiều thành phần A-T, khiến cho các mạch có thể tách rời dễ dàng.
Trong phòng thí nghiệm, cường độ của tương tác này có thể đo bằng cách tìm ra nhiệt độ nóng chảy Tm cần thiết để phân tách một nửa liên kết hydro giữa hai mạch. Khi tất cả các cặp base nóng chảy, hai mạch của chuỗi DNA sẽ tách rời và tồn tại trong dung dịch như 2 phân tử hoàn toàn độc lập. Những phân tử mạch đơn DNA không có hình dạng chung, nhưng một số cấu trúc ổn định hơn cấu trúc khác.
Có nghĩa và đối nghĩa
Một trình tự DNA gọi là "có nghĩa" (sense) nếu trình tự của nó giống với trình tự của bản sao RNA thông tin dùng để dịch mã thành protein. Khi đó, trình tự trên mạch bổ sung còn lại được gọi là trình tự "đối nghĩa" (antisense). Cả trình tự có nghĩa và đối nghĩa có thể tồn tại trên các đoạn khác nhau của cùng một mạch đơn DNA (tức là cả hai mạch có thể chứa cả trình tự có nghĩa lẫn đối nghĩa). Ở tế bào nhân thực và nhân sơ, các trình tự RNA đối nghĩa đều được tạo ra, nhưng chức năng của những RNA này vẫn chưa được hiểu rõ hoàn toàn. Có đề xuất cho rằng các RNA đối nghĩa có khả năng tham gia vào hoạt động điều hòa biểu hiện gene thông qua sự bổ sung base RNA-RNA.
Một vài trình tự DNA ở sinh vật nhân thực và nhân sơ, và hay gặp hơn ở plasmid và virus, xóa nhòa sự khác biệt giữa những mạch có nghĩa và đối nghĩa do có sự hiện diện của các gene chồng lợp (overlapping gene). Trong trường hợp này, một số trình tự DNA đảm nhận đến hai trách nhiệm, mã hóa cho một protein khi đọc dọc theo một mạch, và mã hóa protein thứ hai khi đọc theo hướng ngược lại dọc theo mạch kia. Trong vi khuẩn, sự chồng lợp này có thể tác động đến quá trình điều hòa phiên mã gene, trong khi ở virus, các gene chồng lợp lại làm tăng lượng thông tin được mã hóa bên trong bộ gene nhỏ bé của virus.
DNA siêu xoắn
DNA có thể xoắn lại tựa như một sợi dây thừng theo một tiến trình gọi là DNA siêu xoắn (DNA supercoiling). Với DNA ở trạng thái "bình thường", một mạch thường xoắn đều quanh trục tưởng tượng của chuỗi xoắn kép theo từng đoạn ngắn mang khoảng 10,4 cặp base, nhưng nếu DNA bị vặn xoắn thì các mạch có thể trở nên siết chặt hơn hoặc lỏng lẻo hơn. Nếu DNA bị xoắn theo hướng của chuỗi xoắn kép, hay siêu xoắn thuận (positive supercoiling), thì các base giữ chặt với nhau hơn. Còn nếu DNA bị xoắn ngược hướng với chuỗi xoắn kép, hay siêu xoắn nghịch (negative supercoiling), thì các base phân tách dễ dàng hơn. Trong tự nhiên, hầu hết DNA trong tế bào đều ở trạng thái gần siêu xoắn nghịch do chịu sự tác động của nhóm enzyme có tên gọi topoisomerase. Những enzyme này cũng cần thiết để tháo xoắn các mạch DNA trong những quá trình như phiên mã và nhân đôi DNA.

Mô hình cấu trúc DNA khác
DNA tồn tại ở nhiều cấu trúc, trong đó bao gồm dạng A, B, và Z, thế nhưng chỉ có cấu trúc B và Z là trực tiếp quan sát thấy trong những sinh vật chức năng. Cấu trúc DNA tương ứng phụ thuộc vào mức độ hydrat hóa, trình tự DNA, số lượng và chiều hướng siêu xoắn, các tu sửa hóa học trên base, loại và hàm lượng ion kim loại, cũng như sự hiện hữu của polyamin trong dung dịch.
Báo cáo đầu tiên về các mẫu nhiễu xạ tia X của dạng A và B—họ sử dụng phương pháp phân tích dựa trên hàm Patterson chỉ cung cấp một lượng thông tin giới hạn về cấu trúc của các sợi định hướng DNA (oriented fibers). Một phân tích khác, do Wilkins cùng cộng sự (et al.) đề xướng vào năm 1953, cho biết các mẫu nhiễu xạ tia X in vivo DNA dạng B của các sợi DNA hydrat hóa cao tuân theo bình phương hàm Bessel. Trong cùng tạp chí, James Watson và Francis Crick trình bày phân tích mô hình phân tử DNA của họ các mẫu nhiễu xạ tia X và gợi ý rằng cấu trúc của DNA là chuỗi xoắn kép.
Dạng B là cấu trúc phổ biến nhất tìm thấy dưới những điều kiện của tế bào sống, tồn tại ở trạng thái gần giống tinh thể (paracrystalline state), đó là cấu trúc động mặc dù tính tương đối cứng của chuỗi xoắn kép DNA được giữ ổn định bởi liên kết hydro giữa các base. Để đơn giản, hầu hết những mô hình phân tử DNA đều bỏ qua liên kết động lực của nước và các ion đối với phân tử dạng B , và do đó ít hữu ích khi dùng các mô hình này để hiểu cách hoạt động của dạng B trong tế bào sống ở trạng thái bình thường (in vivo). Phân tích vật lý và toán học của ảnh chụp tia X cũng như dữ liệu quang phổ thu được cho dạng B tiền tinh thể (paracrystalline), do vậy phức tạp hơn so với dữ liệu nhiễu xạ tia X của ảnh chụp dạng A.
So với dạng B, dạng A xoắn ốc theo chiều tay phải rộng hơn, có rãnh nhỏ nông và rộng, trong khi rãnh lớn sâu hơn và hẹp hơn. Dạng A thường xuất hiện dưới các điều kiện phi sinh lý trong các mẫu DNA khử nước một phần, trong khi ở tế bào nó có thể ở dạng lai ghép 2 mạch đơn DNA với mạch đơn RNA, cũng như trong phức hệ enzym-DNA. Ở đoạn DNA nơi các base đã bị tu sửa về mặt hóa học bằng quá trình methyl hóa có thể trải qua sự thay đổi lớn về hình dạng cấu trúc và trở thành dạng Z. Ở cấu trúc này hai mạch xoắn quanh trục theo chiều tay trái, ngược chiều với hướng của dạng B phổ biến. Những cấu trúc bất thường này có thể nhận ra bằng loại protein đặc hiệu liên kết với DNA dạng Z và có thể tham gia vào quá trình điều hòa phiên mã.
| Đặc tính hình học | A-DNA | B-DNA | Z-DNA |
|---|---|---|---|
| Chiều xoắn | phải | phải | trái |
| Đường kính | ≈ 2,3 nm | ≈ 2,0 nm | ≈ 1,8 nm |
| Đơn vị lặp lại | 1 bp | 1 bp | 2 bp |
| Góc quay/bp | 32,7° | 34,3° | 60°/2 |
| Số bp trung bình/vòng xoắn | 11 | 10,4 | 12 |
| Độ nghiêng của bp so với trục | +19° | -1,2° | -9° |
| Độ dài dốc/bp dọc theo trục | 0,23 nm | 0,332 nm | 0,38 nm |
| Bước/vòng xoắn | 2,82 nm | 3,32 nm | 4,56 nm |
| Góc xoắn trung bình giữa hai bp | +18° | +16° | 0° |
| Góc glycosyl | anti | anti | Pyrimidine: anti Purine: syn |
| Chế độ gấp phân tử đường (sugar puckering) |
C3'-endo | C2'-endo | Pyrimidine: C2'-endo Purine: C3'-endo |
| Rãnh lớn | hẹp và sâu | rộng và sâu, độ sâu: 0,85 nm | phẳng |
| Rãnh nhỏ | rộng và phẳng | hẹp và sâu, độ sâu: 0,75 nm | hẹp và sâu |
DNA có thành phần hóa học thay thế
Trong một vài năm, các nhà sinh học vũ trụ đã đề xuất về một sinh quyển bóng tối (shadow biosphere), một sinh quyển vi sinh vật giả thuyết tồn tại trên Trái Đất mà sử dụng các quá trình phân tử và hóa học khác căn bản so với những gì đã biết về sự sống hiện tại. Một trong các đề xuất đó là sự tồn tại của dạng sinh vật sống mà nguyên tử asen thay cho phospho trong DNA. Một báo cáo năm 2010 cho thấy khả năng này có mặt trong vi khuẩn GFAJ-1, mặc dù đã có những tranh cãi, và cuối cùng năm 2012 một báo cáo khác nêu ra bằng chứng cho thấy các vi khuẩn này chủ động ngăn không cho asen kết hợp vào bộ khung DNA của nó và những phân tử sinh học khác.
Cấu trúc 4 sợi
Tại đầu mút của mỗi nhiễm sắc thể tuyến tính có những vùng chuyên biệt của DNA gọi là telomere. Chức năng chính của các vùng này đó là cho phép tế bào tái bản các đầu mút nhiễm sắc thể bằng cách sử dụng enzym telomerase, bởi vì bình thường các enzym tái bản DNA không thể nhân đôi đầu cực 3′ của nhiễm sắc thể. Những đầu mũ đặc hiệu này của nhiễm sắc thể cũng giúp bảo vệ đầu cực của DNA bị rút ngắn, và ngăn hệ thống sửa chữa DNA trong tế bào coi DNA bị hỏng cần được sửa chữa. Trong tế bào người, các telomere thường là những đoạn mạch đơn DNA chứa vài nghìn trình tự TTAGGG lặp đi lặp lại đơn giản.
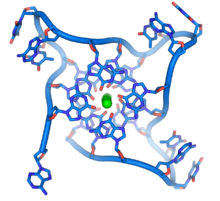
Các trình tự giàu guanine giữ ổn định đầu mút của nhiễm sắc thể bằng cách hình thành nên cấu trúc gồm những đơn vị bốn base xếp chồng, hơn là bắt cặp bổ sung tìm thấy ở các phân tử DNA khác. Ở đây, bốn base, được gọi là 4 guanin tetrad, tạo thành một tấm phẳng. Sau đó, bộ 4 base phẳng này xếp chồng lẫn nhau hình thành nên cấu trúc G-quadruplex (cấu trúc 4 sợi) ổn định. Cấu trúc này được ổn định bởi liên kết hydro và chelat hóa ion kim loại nằm ở trung tâm của mỗi đơn vị bốn base. Những cấu trúc khác cũng có thể tồn tại, trung tâm của bộ bốn base đến từ một mạch đơn uốn quanh các base, hoặc là một vài mạch song song với nhau, trong đó mỗi mạch đều đóng góp một base vào cấu trúc trung tâm.
Bên cạnh cấu trúc xếp chồng, telomere cũng tạo thành cấu trúc dạng vòng lớn gọi là telomere loop, hay T-loop. Trong cấu trúc này, DNA mạch đơn cuộn quanh thành một vòng tròn dài được ổn định bởi các protein liên kết với telomere. Tại đầu mút của T-loop, DNA telomere mạch đơn được cho vào một vùng bao bởi DNA mạch kép bằng mạch telomere phân tách DNA mạch kép và bắt cặp bổ sung với một trong hai mạch. Cấu trúc mạch ba này (triple-stranded) được gọi là vòng 3 sợi (displacement loop) hay D-loop.
|

|
| Nhánh đơn mạch | Nhánh đa mạch |
DNA phân nhánh
Ở chuỗi xoắn kép DNA, hiện tượng sờn tước đầu mút xuất hiện khi những đoạn không được bổ sung hiện diện tại đầu mút của DNA mạch kép. Qua đó, DNA phân nhánh có thể hình thành nếu có một mạch DNA thứ ba xuất hiện và mang những đoạn mới liên hợp với đoạn không được bổ sung của chuỗi xoắn kép đã bị sờn tước trước đó. Dạng đơn giản nhất của DNA phân nhánh chỉ bao gồm ba mạch DNA, tất nhiên là có thể tồn tại thêm nhiều nhánh phức tạp khác. DNA phân nhánh được ứng dụng trong công nghệ nano để lắp ráp những cấu hình phân tử mong muốn.
Tu sửa base và trình tự của DNA
|

|

|
| Cytosine | 5-methylcytosine | Thymine |
Tu sửa base và bao gói DNA
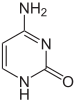
Biểu hiện của gene chịu ảnh hưởng bởi phương cách đóng gói DNA trong nhiễm sắc thể, thành một cấu trúc gọi là chất nhiễm sắc (chromatin). Những tác động chỉnh sửa base có thể xảy ra trong quá trình đóng gói, với các vùng không có hoặc có mức biểu hiện gene thấp thông thường chứa các base cytosine ở mức methyl hóa cao. Sự đóng gói DNA và ảnh hưởng của nó lên biểu hiện gene cũng xảy ra bởi hiệu ứng thay đổi liên kết cộng hóa trị tại lõi protein histone bọc quanh DNA trong cấu trúc chất nhiễm sắc hoặc bởi phức hệ chất nhiễm sắc tái mô hình hóa (xem Tái mô hình hóa chất nhiễm sắc (chromatin remodeling)). Do vậy, tác động xen lẫn giữa methyl hóa DNA và thay đổi liên kết ở histone có ảnh hưởng phối hợp đến chất nhiễm sắc và biểu hiện gene.
Ví dụ, sự methyl hóa cytosine, tạo ra 5-methylcytosine, có vai trò quan trọng đối với sự bất hoạt X của nhiễm sắc thể (X-inactivation). Mức độ methyl hóa trung bình thay đổi theo mỗi sinh vật – giun tròn Caenorhabditis elegans không có phản ứng methyl hóa cytosine, trong khi ở động vật có xương sống có mức độ cao hơn, lên tới 1% lượng DNA chứa 5-methylcytosine. Tuy 5-methylcytosine có vai trò quan trọng, nhưng nó vẫn có thể bị khử amin hóa để chuyển thành base thymine, do đó cytosine methyl hóa có khuynh hướng gây đột biến. Những thay đổi base khác bao gồm sự methyl hóa adenine ở vi khuẩn, sự hiện diện của 5-hydroxymethylcytosine trong não, và sự glycosyl hóa của uracil tạo thành "Base J" trong các loài Kinetoplastida.
Hư hại
DNA có thể bị hư hại bởi nhiều tác nhân đột biến, làm thay đổi trình tự DNA. Những tác nhân đột biến bao gồm các chất oxy hóa, ankyl hóa với cả bức xạ điện từ năng lượng cao như tia cực tím và tia X. Loại hư hại DNA được tạo ra phụ thuộc vào loại tác nhân đột biến. Ví dụ, tia UV có thể phá hủy DNA bằng cách tạo ra dimer thymine, nghĩa là liên kết chéo giữa các base của pyrimidine với nhau. Mặt khác, những tác nhân oxy hóa như gốc tự do hay hydro peroxide tạo ra nhiều dạng hư hại, bao gồm tu sửa base, đặc biệt là guanosine, và đứt gãy chuỗi xoắn kép. Một tế bào điển hình ở người chứa khoảng 150.000 base chịu tổn thương do bị oxy hóa. Trong số những tổn thương oxy hóa, nguy hiểm nhất đó là chuỗi xoắn kép bị đứt gãy, vì rất khó để gắn lại và có thể dẫn tới đột biến mất, thêm và thay thế trên trình tự DNA, cũng như là chuyển đoạn nhiễm sắc thể (chromosomal translocation). Những đột biến này có thể gây ra ung thư. Bởi vì những giới hạn vốn có trong cơ chế sửa chữa DNA, nên nếu con người sống đủ lâu, thì những hư hại này cuối cùng sẽ dẫn tới sự phát triển của ung thư. Những hư hại DNA xảy ra tự nhiên, là do các quá trình bình thường trong tế bào tạo ra các gốc tự do oxy hóa (ROS), chẳng hạn các phản ứng thủy phân của nước trong tế bào, v.v, cũng xảy ra thường xuyên. Mặc dù hầu hết những hư hại này đều sẽ được sửa chữa, nhưng trong bất kỳ tế bào nào vẫn có một số hư hại DNA có thể còn tồn tại mặc cho các hoạt động của quá trình sửa chữa. Những hư hại DNA còn sót lại sẽ tích tụ dần theo độ tuổi bên trong các mô hậu nguyên phân của động vật có vú. Sự tích tụ này dường như là một nguyên nhân quan trọng dẫn tới sự già yếu.
Nhiều tác nhân đột biến nằm gọn trong không gian giữa hai cặp base liền kề, hay gọi là sự xen kẹp (intercalation). Hầu hết các chất xen kẹp là những phân tử vòng thơm và vòng phẳng; ví dụ như: ethidium bromide, acridine, daunomycin và doxorubicin. Để cho một chất xen kẹp có thể vừa vặn không gian giữa hai cặp base, các base phải tách ra, bóp méo mạch DNA bằng cách tháo xoắn chuỗi xoắn kép. Điều này khiến ức chế quá trình phiên mã và nhân đôi DNA, gây ra độc tính và đột biến. Do đó, các phân tử xen kẹp vào DNA có thể là tác nhân gây ung thư, và trong trường hợp của thalidomide là tác nhân gây quái thai (teratogen). Những phân tử khác như benzo[a]pyrene diol epoxide và aflatoxin tạo thành sản phẩm cộng vào DNA gây ra lỗi trong quá trình nhân đôi. Tuy nhiên, do khả năng ức chế phiên mã và nhân đôi DNA, những độc tố tương tự khác cũng được sử dụng trong hóa trị liệu để ức chế phát triển nhanh chóng của các tế bào ung thư.
Chức năng sinh học

DNA thông thường hiện diện trong nhiễm sắc thể dạng thẳng ở sinh vật nhân thực, và nhiễm sắc thể dạng vòng ở sinh vật nhân sơ. Nhiễm sắc thể (chromosome) thực chất là chất nhiễm sắc (chromatin) bị co xoắn từ kỳ đầu của quá trình phân bào. Còn chất nhiễm sắc chính là phức hợp giữa chuỗi xoắn kép DNA với các protein histone và phi histone gói gọn thành một cấu trúc cô đặc. Điều này cho phép các phân tử DNA rất dài nằm gọn trong nhân tế bào. Cấu trúc vật lý của nhiễm sắc thể và chất nhiễm sắc thay đổi luân phiên tùy thuộc vào từng giai đoạn của chu kỳ tế bào. Tập hợp các nhiễm sắc thể trong một tế bào tạo thành bộ gene của nó; bộ gene người có xấp xỉ 3 tỷ cặp base DNA xếp thành 46 nhiễm sắc thể. Thông tin chứa trong DNA tổ chức dưới dạng trình tự của các đoạn DNA gọi là gene. Sự kế thừa thông tin di truyền trong gene được thực hiện thông qua các cặp base bổ sung. Ví dụ, trong quá trình phiên mã, khi một tế bào sử dụng thông tin ở một gene, trình tự DNA sẽ được sao mã vào trình tự bổ sung RNA thông qua lực hút giữa DNA và các nucleotide chính xác của RNA. Thông thường, bản sao RNA này được dùng làm khuôn mẫu để xác định trình tự các amino acid trong quá trình dịch mã, thông qua sự tương tác giữa các nucleotide RNA. Trong quá trình khác, một tế bào có thể tự sao chép thông tin di truyền của nó bằng quá trình nhân đôi DNA. Chi tiết của những chức năng này được nêu trong những bài viết liên quan; bài này tập trung vào tương tác giữa DNA và các phân tử khác mà đảm trách các chức năng của bộ gene.
Gene và bộ gene

DNA chứa các đoạn gene được gói gọn và xếp chặt có thứ tự bởi quá trình cô đặc DNA (DNA condensation), để có thể vừa vặn trong một thể tích nhỏ của tế bào. Ở sinh vật nhân thực, DNA nằm trong nhân tế bào, cùng với một lượng nhỏ nằm trong ty thể và lục lạp. Ở sinh vật nhân sơ, DNA nằm trong một thể có hình dạng không đều giữa tế bào chất, gọi là thể nhân (hoặc vùng nhân, nucleoid). Thông tin di duyền trong một bộ gene được lưu trữ bởi các gene, và tập hợp toàn bộ các gene trong tế bào của cơ thể thuộc một loài sinh vật được gọi là kiểu gene. Mỗi gene là một đơn vị của tính di truyền và là một đoạn của DNA có ảnh hưởng tới một đặc tính cụ thể trong cơ thể sinh vật. Các gene chứa một khung đọc mở (open reading frame) có thể được phiên mã, cùng với các vùng trình tự điều hòa (regulatory sequence) như vùng khởi động (promoter) và vùng tăng cường (enhancer) có khả năng điều hòa quá trình phiên mã của khung đọc mở.
Ở nhiều loài, chỉ một phần nhỏ trong tổng số trình tự của bộ gene là mã hóa cho protein. Ví dụ, chỉ khoảng 1,5% bộ gene người chứa các đoạn exon mã hóa cho protein, trong khi trên 50% DNA ở người chứa các trình tự lặp lại không mã hóa (non-coding repeated sequence). Những lý do cho sự có mặt của rất nhiều DNA không mã hóa ở bộ gene của sinh vật nhân thực và sự cách biệt rất lớn trong kích cỡ bộ gene, hay giá trị C, giữa các loài đã đưa đến một vấn đề nan giải lâu năm gọi là "nghịch lý giá trị C". Tuy nhiên, một số trình tự DNA không mã hóa protein vẫn có thể có chức năng mã hóa các phân tử RNA không mã hóa tham gia vào quá trình điều hòa biểu hiện gene.

Một số trình tự DNA không mã hóa đóng vai trò cấu trúc bộ khung trong nhiễm sắc thể. Telomere và tâm động (centromere) điển hình chỉ chứa vài gene, nhưng lại có vai trò quan trọng đối với chức năng và sự ổn định của nhiễm sắc thể. Một dạng DNA không mã hóa xuất hiện ở người gọi là gene giả (pseudogene), là những bản sao của gene nhưng đã bị bất hoạt do tác động của đột biến. Những trình tự này thường chỉ là các hóa thạch phân tử, mặc dù chúng có thể phục vụ như là vật liệu di truyền dạng thô cho sự sản sinh gene mới thông qua quá trình nhân đôi (gene duplication) và phân ly gene.
Phiên mã và dịch mã

Mỗi gene là một đoạn trình tự DNA chứa thông tin di truyền và có thể ảnh hưởng đến kiểu hình của sinh vật. Bên trong một gene, trình tự các base dọc theo một mạch DNA xác định nên trình tự của RNA thông tin, rồi từ đó xác lập nên trình tự của một hay nhiều protein. Mối liên hệ giữa trình tự nucleotide của các gene và trình tự các amino acid của protein được xác định bởi những quy tắc trong quá trình dịch mã, được biết đến với cái tên bộ mã di truyền. Mỗi mã di truyền chứa bộ ba 'chữ cái' gọi là triplet (bộ ba mã gốc) trên DNA hay codon (bộ ba mã sao) trên mRNA hay anticodon (bộ ba đối mã) trên tRNA tạo thành một trình tự gồm ba nucleotide (v.d. ACT, CAG, TTT trên mạch gốc DNA).
Trong quá trình phiên mã, các triplet của một gene được sao chép sang RNA thông tin thành các codon tương ứng bằng enzyme RNA polymerase. Bản sao RNA này sau đó được giải mã bởi ribosome thông qua hoạt động đọc trình tự RNA bằng cách bổ sung cặp base trong RNA thông tin với RNA vận chuyển, loại phân tử mang theo amino acid. Vì có bốn loại base khác nhau được tổ hợp thành các mã bộ ba, do vậy có tất cả 64 codon (tổ hợp 43). Tất cả chúng được phân bổ để mã hóa cho 20 loại amino acid cơ bản của sự sống, do đó một amino acid có thể có nhiều hơn một codon mã hóa cho nó. Bên cạnh đó cũng có ba codon 'kết thúc' hoặc 'vô nghĩa' (nonsense) đánh dấu điểm kết thúc của một vùng mã hóa; chúng là các codon UAA, UAG và UGA (tương ứng với các triplet TAA, TAG và TGA).
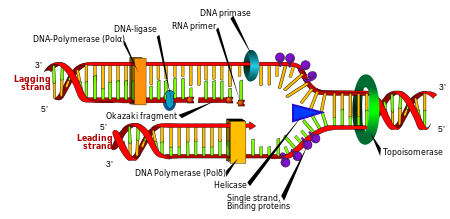
Nhân đôi DNA (sao chép, tái bản)
Phân bào là quá trình cơ bản của sinh vật để có thể sinh trưởng, nhưng khi một tế bào phân chia, nó phải nhân đôi DNA trong bộ gene của nó sao cho hai tế bào con có cùng thông tin di truyền như của tế bào mẹ. Cấu trúc mạch kép DNA giúp hình thành một cơ chế đơn giản cho quá trình nhân đôi DNA. Ở đây, hai mạch đơn tháo xoắn tách rời nhau và mỗi mạch mới bổ sung với mỗi mạch gốc được tổng hợp bằng một loại enzyme gọi là DNA polymerase. Enzyme này tạo ra những mạch mới bằng cách tìm những nucleotide tự do từ môi trường nội bào và gắn kết chính xác với nucleotide trên mạch gốc ban đầu theo nguyên tắc bổ sung. Vì DNA polymerase chỉ tổng hợp mạch mới theo chiều 5′ → 3′, do vậy trên mạch khuôn có chiều 3' → 5' thì mạch bổ sung được tổng hợp liên tục do cùng chiều với chiều tháo xoắn. Còn trên mạch khuôn có chiều 5' → 3' thì mạch bổ sung được tổng hợp ngắt quãng tạo nên các đoạn ngắn gọi là đoạn Okazaki do ngược chiều với chiều tháo xoắn, sau đó các đoạn này được nối lại với nhau nhờ enzyme nối DNA ligase.
acid nucleic ngoại bào
DNA ngoại bào trần (extracellular DNA - eDNA), hầu hết được giải phóng khi tế bào chết đi, xuất hiện khắp nơi trong môi trường. Mức độ tập trung của nó trong đất có thể lên tới 2 μg/lít, và trong môi trường nước tự nhiên lên tới 88 μg/lít. Đã có một số chức năng khả thi của eDNA được đề xuất: nó có thể tham gia vào chuyển gene ngang; cung cấp dinh dưỡng; và có khả năng hoạt động như một chất đệm để khôi phục hoặc chuẩn độ ion hoặc tính kháng sinh. DNA ngoại bào hoạt động như một thành phần chức năng của chất nền ngoại bào trong lớp màng vi sinh vật (phim sinh học - biofilm) của một số loài vi khuẩn. Nó có thể hoạt động như một nhân tố nhận diện để điều phối sự bám dính và phân tán của một số loại tế bào đặc hiệu trong phim sinh học; hoặc đóng góp vào sự hình thành phim sinh học; cũng như đóng góp vào đặc tính vật lý chắc chắn của phim sinh học và sức đề kháng trước những căng thẳng sinh học (biological stress).
Tương tác với protein
Mọi chức năng của DNA phụ thuộc vào tương tác với protein. Những tương tác protein này có thể không đặc hiệu hoặc đặc hiệu khi protein liên kết với một trình tự DNA cụ thể. Các enzyme cũng liên kết với DNA và trong số này, những enzyme polymerase sao chép trình tự base của DNA trong quá trình phiên mã và nhân đôi DNA có vai trò đặc biệt quan trọng.
Protein liên kết DNA

|
Các protein cấu trúc liên kết với DNA là những ví dụ đã được nghiên cứu khá kĩ về tương tác không đặc hiệu DNA-protein. Bên trong nhiễm sắc thể, DNA được giữ trong phức hợp với protein cấu trúc. Những protein này tổ chức DNA thành một cấu trúc thắt đặc gọi là chất nhiễm sắc (chromatin). Trong sinh vật nhân thực, cấu trúc này bao gồm DNA liên kết với phức hợp các đơn vị protein cơ sở nhỏ gọi là histone, trong khi ở sinh vật nhân sơ lại có nhiều loại protein tham gia hơn. Các histone tạo thành một phức hợp dạng đĩa gọi là nucleosome, với chuỗi xoắn kép DNA bao quanh bề mặt cấu trúc bằng hai vòng xoắn. Những tương tác không đặc hiệu được hình thành thông qua các phần dư cơ bản trong histone, tạo ra liên kết ion với bộ khung đường-phosphat có tính acid của DNA, và do vậy phần lớn tương tác là độc lập với trình tự các base. Những phản ứng hóa học làm thay đổi các amino acid cơ bản này bao gồm phản ứng methyl hóa, phosphoryl hóa và acethyl hóa. Những thay đổi hóa học này làm ảnh hưởng tới cường độ tương tác giữa DNA và histone, khiến cho các nhân tố phiên mã trở nên dễ dàng hoặc khó tiếp cận được với DNA và do vậy thay đổi tốc độ quá trình phiên mã. Những protein liên kết DNA không đặc hiệu khác trong chất nhiễm sắc bao gồm các nhóm protein có tính linh động cao mà khi liên kết có thể uốn hoặc làm vặn DNA. Các protein này có vai trò quan trọng trong việc sắp uốn nucleosome và xếp đặt chúng thành những cấu trúc lớn hơn tạo thành nhiễm sắc thể.
Có một nhóm protein liên kết DNA đặc biệt là các protein chỉ liên kết đặc hiệu với một mạch đơn DNA. Ở người, protein A phục vụ quá trình nhân đôi DNA là protein được hiểu biết rõ ràng nhất trong nhóm này và tham gia vào những quá trình khi hai mạch xoắn kép đã tách rời nhau, bao gồm sao chép DNA, tái tổ hợp và sửa chữa DNA. Những protein liên kết này giúp ổn định hóa mạch đơn DNA và bảo vệ nó khỏi hiện tượng hình thành cấu trúc vòng gấp kẹp tóc (stem-loop/hairpin loop) hoặc bị phân cắt bởi enzyme nuclease.

Ngược lại, có những protein khác phải biến đổi cấu hình để liên kết với những trình tự DNA riêng biệt. Lĩnh vực nghiên cứu sâu rộng nhất về những protein này đó là nghiên cứu nhiều loại nhân tố phiên mã (transcription factor) khác nhau, đây chính là các protein điều hòa quá trình phiên mã. Mỗi nhân tố phiên mã liên kết với một tập hợp cụ thể các trình tự DNA và kích hoạt hoặc ức chế hoạt động phiên mã của gene tại những trình tự gần với vùng khởi động của chúng. Nhân tố phiên mã thực hiện vai trò này theo hai cách. Đầu tiên, chúng có thể gắn với RNA polymerase chịu trách nhiệm cho quá trình phiên mã, hoặc trực tiếp hoặc gián tiếp thông qua các protein trung gian; giúp định vị polymerase tại vùng gene khởi động và cho phép bắt đầu phiên mã. Hoặc cách khác, nhân tố phiên mã có thể gắn với enzyme làm biến đổi các histone ở vùng khởi động. Điều này làm thay đổi khả năng tiếp cận của polymerase với mạch khuôn DNA.
Do những DNA đích này xuất hiện trong toàn thể bộ gene sinh vật, vì vậy những thay đổi trong hoạt động của một loại nhân tố phiên mã có thể ảnh hưởng tới hàng nghìn gene. Hệ quả là, những protein này thường là mục tiêu của các quá trình truyền tín hiệu tải nạp (signal transduction) mà điều khiển sự đáp ứng đối với những thay đổi của môi trường hoặc biệt hóa tế bào và điều khiển sự phát triển. Nét đặc trưng của những tương tác của các nhân tố phiên mã với DNA đến từ các protein tạo nhiều tiếp xúc với các cạnh của các base DNA, cho phép chúng "đọc" được trình tự DNA. Phần lớn những tương tác với base diễn ra ở rãnh lớn, nơi có thể tiếp xúc nhiều nhất với các base.

Enzyme chỉnh sửa DNA
Nuclease và ligase
Nuclease là các enzyme có khả năng cắt mạch DNA bằng cách xúc tác cho phản ứng thủy phân các liên kết phosphodieste. Loại nuclease thủy phân nucleotide từ những đầu mút của mạch DNA được gọi là exonuclease, trong khi endonuclease lại phân cắt từ những điểm trong mạch. Những nuclease được sử dụng thường xuyên nhất trong sinh học phân tử là các endonuclease giới hạn, do chúng cắt DNA tại những đoạn trình tự đặc hiệu. Ví dụ, enzyme EcoRV ở hình ảnh bên trái nhận ra trình tự gồm 6 base 5′-GATATC-3′ và thực hiện việc cắt theo một đường nằm ngang. Trong tự nhiên, những enzyme này bảo vệ vi khuẩn chống lại sự tấn công của thể thực khuẩn bằng cách tiêu hóa DNA thể thực khuẩn khi chúng xâm nhập vào tế bào vi khuẩn, lúc này các enzyme hoạt động như một phần trong hệ thống hạn chế cải biến (restriction modification system). Trong công nghệ sinh học, những nuclease hoạt động với các trình tự đặc hiệu được sử dụng trong tách dòng phân tử (molecular cloning) và kỹ thuật nhận diện DNA (DNA profiling).
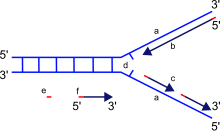
a: mạch khuôn, b: mạch dẫn đầu (leading strand), c: mạch theo sau (lagging strand), d: chạc tái bản, e: đoạn mồi RNA, f: các đoạn Okazaki
Những enzyme có chức năng nối lại những đoạn DNA bị cắt hoặc bị đứt gãy được gọi là DNA ligase.Ligase đặc biệt quan trọng trong việc nối lại các mạch theo sau ngắt quãng của DNA, tức là các đoạn Okazaki tại chạc tái bản thành một bản sao hoàn chỉnh từ mạch khuôn DNA. Chúng cũng tham gia vào việc sửa chữa DNA và tái tổ hợp di truyền.
Topoisomerase và helicase
- Topoisomerase là những enzyme mang hoạt tính của cả nuclease lẫn ligase. Những protein này có khả năng thay đổi cấu trúc chuỗi xoắn kép DNA: chúng có thể thoái bỏ trạng thái siêu xoắn, hoặc ngược lại, chúng đóng xoắn. Một số enzyme trong nhóm này thực hiện hoạt động cắt chuỗi xoắn kép DNA và cho phép một phần phân tử quay được, do vậy làm giảm mức siêu xoắn của nó; sau cuối enzyme sẽ gắn khít hoàn chỉnh lại đoạn DNA bị gãy. Những loại enzyme khác có thể cắt một chuỗi xoắn kép DNA và rồi kéo một mạch DNA thứ hai vào vị trí cắt này, trước khi thực hiện việc nối lại chuỗi xoắn kép. Topoisomerase cần thiết cho nhiều quá trình liên quan đến DNA, như nhân đôi và phiên mã.
- Helicase là những protein thuộc một trong những loại động cơ phân tử. Chúng sử dụng năng lượng hóa học trong nucleoside triphosphat, thường sử dụng nhất là adenosine triphosphat (ATP), để phá vỡ liên kết hydro giữa các base và tháo xoắn chuỗi kép DNA thành hai mạch đơn. Những enzyme này có vai trò quan trọng thiết yếu đối với hầu hết quá trình enzyme cần thiết có tương tác với các base nitơ.
Polymerase
Polymerase là những enzyme thực hiện tổng hợp mạch polynucleotide từ nucleoside triphosphat. Tính tuần tự của các sản phẩm của chúng được sinh ra dựa trên những mạch polynucleotide đã có—gọi là mạch khuôn. Những enzyme này hoạt động bằng lần lượt thêm vào một nucleotide tại nhóm 3′ hydroxyl ở điểm cuối của mạch polynucleotide đang phát triển. Kết quả là, mọi polymerase hoạt động luôn theo chiều từ đầu 5′ đến đầu 3′. Tại trung tâm hoạt động của các enzyme này, phân tử nucleoside triphosphat đi đến ghép cặp với base của mạch khuôn: điều này cho phép polymerase tổng hợp một cách chính xác mạch bổ sung đối với mạch khuôn của nó. Các polymerase được phân loại theo các nhóm mạch khuôn mà chúng sử dụng.
Trong quá trình sao chép DNA, DNA polymerase phụ thuộc DNA tạo nên những bản sao của những mạch polynucleotide DNA. Để bảo toàn thông tin sinh học, điều cơ bản là trình tự của các base trong mỗi bản sao là trình tự bổ sung chính xác cho trình tự base trong mạch khuôn mẫu. Nhiều DNA polymerase có hoạt tính đọc và sửa sai (proofreading). Ở đây, polymerase nhận ra các lỗi thường xuất hiện trong phản ứng tổng hợp do sự thiếu đi những base ghép cặp giữa các nucleotide không khớp với nhau. Nếu polymerase phát hiện một sự không ăn khớp, hoạt tính exonuclease 3'-5′ được kích hoạt và base không khớp nào được phát hiện sẽ bị cắt bỏ. Trong hầu hết các sinh vật, DNA polymerase hoạt động trong một phức hệ lớn gọi là replisome có chứa nhiều tiểu đơn vị phụ, như protein kẹp DNA (DNA clamp) hay helicase.
DNA polymerase phụ thuộc RNA là những loại polymerase chuyên biệt thực hiện sao chép trình tự của mạch RNA sang DNA. Chúng bao gồm enzyme phiên mã ngược (reverse transcriptase, RT), ví dụ như một enzyme của virut retrovirus tham gia vào quá trình xâm nhập tế bào, và telomerase, cần cho quá trình sao chép telomere. Telomerase là một polymerase khác thường bởi vì nó chứa chính mạch khuôn RNA của nó như là một phần trong cấu trúc của enzyme này.
Sự phiên mã được thực hiện bởi RNA polymerase phụ thuộc DNA thông qua quá trình sao chép trình tự của mạch DNA sang RNA. Để bắt đầu giải mã một gene, RNA polymerase gắn với một trình tự của DNA gọi là vùng khởi động (promoter) và tách hai mạch DNA khỏi nhau. Sau đó nó sao chép trình tự gene vào một RNA thông tin cho đến khi nó đi đến vùng kết thúc (terminator) của DNA, nơi RNA polymerase dừng lại và tách khỏi DNA. Với DNA polymerase phụ thuộc DNA ở người, RNA polymerase II, enzyme thực hiện phiên mã hầu hết các gene trong bộ gene người, hoạt động như là một phần của một phức hệ protein lớn với nhiều tiểu đơn vị phụ và vùng điều hòa khác nhau.
Tái tổ hợp di truyền
|

|
Chuỗi xoắn kép DNA thường không tương tác với những đoạn khác của DNA, và trong tế bào người các nhiễm sắc thể khác nhau thậm chí còn nằm ở những vùng tách biệt trong nhân tế bào gọi là "vùng nhiễm sắc thể" (chromosome territory). Sự tách biệt về không gian giữa các nhiễm sắc thể khác nhau là quan trọng đối với khả năng hoạt động của DNA như là nơi lưu giữ ổn định thông tin di truyền, khi một vài lần nhiễm sắc thể tương tác trong sự trao đổi chéo nhiễm sắc thể xảy ra trong quá trình sinh sản hữu tính, khi ấy tái tổ hợp di truyền mới diễn ra. Trao đổi chéo nhiễm sắc thể là khi hai chuỗi DNA tháo xoắn và tách rời từng mạch đơn ra, trao đổi các đoạn DNA cho nhau rồi tái gắn kết hai mạch đơn lại.
Tái tổ hợp cho phép nhiễm sắc thể trao đổi thông tin di truyền và tạo ra những tổ hợp gene mới, làm tăng hiệu quả của tính chọn lọc tự nhiên và có thể quan trọng đối với sự tiến hóa nhanh chóng cho những protein mới. Tái tổ hợp di truyền cũng bao gồm trong quá trình sửa chữa DNA, đặc biệt trong sự đáp ứng của tế bào đối với sự kiện chuỗi xoắn kép bị đứt gãy.
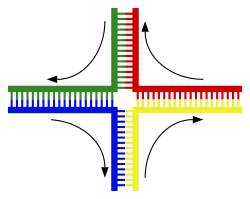
Dạng phổ biến nhất của trao đổi chéo nhiễm sắc thể là tái tổ hợp tương đồng, khi hai nhiễm sắc thể tham gia quá trình trên có trình tự DNA tương đồng. Tái tổ hợp không tương đồng có thể phá hủy tế bào, gây ra chuyển đoạn nhiễm sắc thể và biến dị di truyền. Phản ứng tái tổ hợp được xúc tác bởi các enzyme recombinase, như RAD51. Bước đầu tiên trong quá trình tái tổ hợp là một chuỗi DNA bị đứt gãy do tác động bởi enzyme endonuclease hay những phá hủy đối với DNA. Một loạt các bước tiếp theo có sự xúc tác một phần của recombinase, sau đó hai chuỗi xoắn kép nối lại tại ít nhất một điểm giao Holliday (Holliday junction), trong đó một đoạn của mạch đơn của chuỗi xoắn kép này được ghép nối với đoạn mạch đối ứng của chuỗi xoắn kép kia. Điểm giao Holliday là một cấu trúc tiếp xúc bốn nhánh mà có thể di chuyển dọc theo cặp nhiễm sắc thể, tráo đổi một mạch sang cho mạch khác. Phản ứng tái tổ hợp dừng lại khi điểm giao Holliday bị đứt và xảy ra quá trình hàn gắn lại chuỗi DNA được giải phóng.
Tiến hóa
DNA chứa thông tin di truyền cho phép tất cả dạng sống hiện đại hoạt động chức năng, sinh trưởng và sinh sản. Tuy nhiên, không rõ bao lâu trong hành trình lịch sử 4 tỷ năm của sự sống DNA đã bắt đầu đảm nhận chức năng này, vì có những đề xuất cho rằng các dạng sống xuất hiện sớm nhất có khả năng đã sử dụng phân tử RNA thay vì DNA làm vật liệu di truyền. RNA có thể đã trở thành thành phần trung tâm của quá trình trao đổi chất trong những tế bào sơ khai vì phân tử này có thể vừa truyền đạt thông tin di truyền cũng như mang hoạt tính xúc tác phản ứng dưới dạng ribozyme.Thế giới RNA cổ xưa này, một nơi acid nucleic được sử dụng cho cả quá trình xúc tác và di truyền, có thể ảnh hưởng đến sự tiến hóa của hệ thống mã di truyền hiện tại trên cơ sở bốn loại nucleobase. Điều này thực sự đã xảy ra, vì số lượng của những base khác nhau trong một cơ thể sống như là một sự thỏa hiệp giữa một số lượng nhỏ base tăng cường qua hoạt động nhân đôi chính xác và một số lượng lớn những base tăng cường qua hoạt động xúc tác hiệu quả của ribozyme. Không may thay, thực tế lại không có bằng chứng trực tiếp nào của hệ thống di truyền cổ xưa, như việc phục hồi DNA từ phần lớn các hóa thạch là điều không thể vì phân tử DNA chỉ tồn tại trong môi trường ít hơn một triệu năm và dần dần phân hủy thành những mảnh ngắn tan vào dung dịch. Những yêu cầu khảo sát đối với dạng DNA cổ xưa đã được thực hiện, trong đó báo cáo đáng chú ý nhất là về sự cô lập của một loại vi khuẩn tồn tại phát triển độc lập từ một tinh thể muối có niên đại cách đây 250 triệu năm, tuy nhiên những tuyên bố này vẫn còn trong vòng tranh cãi.
Những thành phần "vữa gạch" của DNA (adenine, guanine và cả những phân tử hữu cơ liên quan) có thể đã hình thành từ vũ trụ trong những khoảng không liên thiên thể. Những hợp chất hữu cơ cấu tạo nền tảng khác của DNA và RNA trong sự sống, bao gồm uracil, cytosine và thymine, cũng đã được tổng hợp trong phòng thí nghiệm dưới các điều kiện mô phỏng tương ứng tìm thấy trong không gian ngoài thiên thể, bằng cách sử dụng những chất hóa học khởi đầu, ví dụ pyrimidine, tìm thấy trong các mảnh vẫn thạch. Pyrimidine, như những hydrocarbon đa vòng thơm (polycyclic aromatic hydrocarbons - PAHs), là hợp chất hóa học giàu carbon nhất tìm thấy trong vũ trụ, có thể được hình thành trong những ngôi sao khổng lồ đỏ hay trong những đám mây khí và bụi giữa các vì sao.
Sử dụng trong công nghệ
Kỹ thuật di truyền
Nhiều phương pháp đã được phát triển để sàng lọc DNA từ sinh vật sống, như chiết lỏng-lỏng phenol-clorofom, và vận dụng trong phòng thí nghiệm, như phương pháp phân hủy giới hạn (restriction digest) và phản ứng chuỗi polymerase. Sinh học hiện đại và ngành hóa sinh sử dụng thường xuyên những kỹ thuật này trong công nghệ tái tổ hợp DNA. Tái tổ hợp DNA là một trình tự DNA nhân tạo được lắp ghép từ các trình tự DNA khác. Chúng có thể được biến nạp vào tế bào sinh vật dưới dạng plasmid hoặc trong những dạng thích hợp khác, bằng cách sử dụng vector virut. Những sinh vật biến đổi di truyền có thể được ứng dụng để sinh ra các sản phẩm như protein tái tổ hợp, sử dụng trong nghiên cứu y học, hoặc được nuôi trồng trong nông nghiệp.
Kỹ thuật nhận diện DNA
Các nhà khoa học pháp y sử dụng DNA trong máu, tinh dịch, da, nước bọt hay tóc tìm thấy tại hiện trường để nhận ra DNA khớp với của một cá nhân, như của thủ phạm chẳng hạn. Quá trình này được gọi là kỹ thuật nhận diện DNA (DNA profiling), hay còn gọi là kỹ thuật in dấu DNA (DNA fingerprintin)). Trong kỹ thuật nhận diện DNA, độ dài của nhiều đoạn DNA lặp lại, như các đoạn trình tự vi vệ tinh (microsatellite) và vệ tinh nhỏ (minisatellite), được so sánh giữa các cá nhân có liên quan. Phương pháp này thường là một kỹ thuật cực kỳ tin cậy cho phép xác định những trình tự DNA ăn khớp với nhau. Tuy vậy, việc nhận dạng có thể trở nên phức tạp nếu tại hiện trường gây án có nhiều DNA của nhiều người. Kỹ thuật nhận diện DNA phát triển vào năm 1984 bởi nhà di truyền học người Anh Sir Alec Jeffreys, và lần đầu tiên được sử dụng trong ngành pháp y để cáo buộc Colin Pitchfork trong vụ án Enderby năm 1988.
Sự phát triển của khoa học pháp y, và khả năng hiện nay có thể nhận ra thông tin di truyền từ các mẫu máu, da, nước bọt hay tóc đã dẫn đến nhiều vụ án phải lật lại hồ sơ mặc dù tòa đã tuyên án. Chứng cứ mà hiện nay có thể được tiết lộ ra trong khi ở thời điểm thẩm vấn là bất khả thi về mặt khoa học. Kết hợp với đạo luật loại bỏ trường hợp bất trùng khả tố (double jeopardy-một người không bị xử hai lần về một tội) ở một số nơi, đã cho phép khởi tố lại một số vụ án khi bản án trước đó đã không nêu được chứng cứ thuyết phục để kết án. Những người mang tội danh nặng được phép yêu cầu lấy mẫu DNA nhằm mục đích so sánh. Trường hợp biện hộ rõ ràng nhất đó là mẫu DNA nhận được từ pháp y bị cho là đã bị ảnh hưởng từ những người ở xung quanh vụ án. Điều này làm cho các thủ tục điều tra trở nên chặt chẽ hơn trong những trường hợp phạm tội mới. Nhận diện DNA cũng được áp dụng thành công cho nhận dạng các nạn nhân trong những vụ tai nạn có thương vong lớn, từ những phần cơ thể, và nhận biết từng nạn nhân trong những mồ chôn tập thể trong chiến tranh, thông qua so sánh với DNA của người nhà nạn nhân.
Kỹ thuật nhận diện DNA cũng được sử dụng để xác thực mối liên hệ sinh học với cha mẹ hoặc ông bà của một đứa trẻ với xác suất chính xác lên tới 99,99%. Những phương pháp kiểm trình tự DNA bình thường được thực hiện sau sinh, nhưng những phương pháp mới có thể kiểm tra quan hệ huyết thống ngay cả khi người mẹ đang mang thai.
DNA enzyme hay xúc tác DNA
Deoxyribozyme, cũng gọi là DNAzyme hay xúc tác DNA phát hiện lần đầu tiên vào năm 1994. Phần lớn chúng là những trình tự mạch đơn DNA được cô lập khỏi một vũng lớn gồm nhiều trình tự DNA ngẫu nhiên thông qua một hướng tiếp cận tổ hợp gọi là kỹ thuật lựa chọn in vitro hay phương pháp SELEX. Những DNAzyme tham gia xúc tác các phản ứng hóa học bao gồm phân cắt RNA-DNA, kết nối RNA-DNA, sự phosphoryl hóa - phản phosphoryl hóa các amino acid, hình thành liên kết carbon-carbon, v.v... DNAzyme có thể tăng cường tốc độ phản ứng hóa học gấp 100.000.000.000 lần so với phản ứng không có sự tham gia xúc tác của nó. Các DNAzyme được nghiên cứu nhiều nhất là những loại phân cắt RNA dùng để phát hiện các ion kim loại khác nhau và thiết kế các tác nhân trị liệu. Một vài DNAzyme đặc hiệu ion kim loại bao gồm GR-5 DNAzyme (đặc hiệu với chì), CA1-3 DNAzymes (với đồng), 39E DNAzyme (với ion uranyl) và NaA43 DNAzyme (với natri). NaA43 DNAzyme, nhạy với natri gấp 10.000 lần so với các ion kim loại khác, được dùng để theo dõi natri theo thời gian thực trong tế bào sống.
Tin sinh học

Tin sinh học bao gồm các kỹ thuật lưu trữ, khai phá dữ liệu, tìm kiếm và thao tác với dữ liệu sinh học, bao gồm dữ liệu về trình tự acid nucleic DNA. Các kỹ thuật này mang đến những ứng dụng rộng rãi trong khoa học máy tính, đặc biệt là thuật toán tìm kiếm chuỗi, học máy và lý thuyết cơ sở dữ liệu. Thuật toán tìm kiếm chuỗi hay so khớp, trong đó tìm kiếm sự xuất hiện của một trình tự các chữ cái trong một trình tự các chữ cái lớn hơn, được phát triển để tìm ra những trình tự nucleotide cụ thể. Trình tự DNA có thể sắp gióng với những trình tự DNA khác để nhận ra các trình tự tương đồng và xác định vị trí đột biến khiến chúng khác biệt. Những kỹ thuật này, đặc biệt là kỹ thuật "sắp gióng đa trình tự" (multiple sequence alignment), được sử dụng để nghiên cứu các mối quan hệ phát sinh chủng loài học và chức năng của protein. Tập hợp dữ liệu của toàn bộ trình tự DNA, như được lập ra bởi Dự án bản đồ gene người, là khó để sử dụng mà không có các chú giải cho phép nhận ra vị trí của các gene hay các yếu tố điều hòa ở mỗi nhiễm sắc thể. Vùng trình tự DNA với những phần đặc trưng gắn với gene mã hóa cho protein hoặc RNA có thể tìm ra bằng thuật toán tìm kiếm gene (gene finding algorithm), cho phép các nhà nghiên cứu dự đoán sự có mặt của những sinh phẩm đặc biệt mã hóa bởi gen và chức năng của chúng trong sinh vật trước khi chúng được phát hiện bằng thực nghiệm. Toàn bộ hệ gene cũng có thể được đối sánh, để làm sáng tỏ lịch sử tiến hóa của từng sinh vật cụ thể và cho phép kiểm tra các sự kiện tiến hóa phức tạp.
Công nghệ nano DNA

Công nghệ nano DNA sử dụng những tính chất tương tác của phân tử DNA và những acid nucleic khác để tạo ra những phức hợp DNA phân nhánh tự lắp ráp có tính năng hữu ích. Do vậy DNA được sử dụng như là vật liệu cấu trúc hơn là vật liệu mang thông tin sinh học. Các nhà khoa học đã tạo ra những dàn lưới hai chiều tuần hoàn (bằng phương pháp lát gạch và origami DNA) và cấu trúc ba chiều đa diện đều.Thiết bị cơ nano và thuật toán tự lắp ráp cũng được chứng minh là khả dĩ, và những cấu trúc DNA này dùng làm khuôn mẫu để sắp xếp các phân tử khác như keo vàng (colloidal gold) và protein streptavidin trong vi khuẩn Streptomyces avidinii.
Lịch sử và nhân chủng học
Bởi vì theo thời gian DNA tích lũy các đột biến, do vậy chúng được di truyền lại, nên DNA chứa thông tin lịch sử, và bằng cách so sánh các trình tự DNA, những nhà di truyền học có thể suy luận ra lịch sử tiến hóa của mỗi loài sinh vật, hay phát sinh chủng loài của chúng. Lĩnh vực phát sinh chủng loài học là một công cụ mạnh của sinh học tiến hóa. Nếu so sánh những trình tự DNA của một loài với nhau, các nhà di truyền quần thể có thể biết được lịch sử phát triển của một quần thể đang nghiên cứu. Kết quả nghiên cứu của ngành này được áp dụng sang cho di truyền sinh thái và nhân chủng học. Ví dụ, các nhà khoa học đã sử dụng bằng chứng DNA để nghiên cứu sự kiện Mười bộ tộc biến mất (Ten Lost Tribes) của Israel.
Lưu trữ thông tin
Trong một bài báo trên tạp chí Nature tháng 1 năm 2013, các nhà khoa học từ Học viện Tin sinh học Châu Âu và công ty Agilent Technologies đã đề xuất một cơ chế sử dụng khả năng mã hóa thông tin của DNA để phục vụ cho việc lưu trữ kỹ thuật số. Nhóm nghiên cứu mã hóa 739 kilobyte dữ liệu vào mã DNA, rồi tổng hợp nên DNA thực thụ, tiếp đó thực hiện giải trình tự DNA và giải mã thông tin ngược trở lại dạng ban đầu, mà họ thông báo là kết quả thu được với độ chính xác 100%. Thông tin được mã hóa chứa các tập tin định dạng văn bản và âm thanh. Một thí nghiệm khác thực hiện trước đó bởi nhóm nghiên cứu ở Đại học Harvard tháng 8 năm 2012, khi nhóm này mã hóa một quyển sách chứa 54.000 từ vào DNA.
Trong tế bào sinh vật sống, thông tin lưu trữ ở DNA có thể được kích hoạt bởi các enzyme. Ví dụ như các kênh ion có protein cảm thụ ánh sáng phối hợp với enzyme xử lý DNA là phù hợp cho nhiệm vụ trên trong ống nghiệm (in vitro). Những phân tử exonuclease huỳnh quang có thể truyền tín hiệu ra bên ngoài tuân theo các trình tự nucleotide mà chúng đọc được.
Lịch sử nghiên cứu DNA

DNA lần đầu tiên được cô lập bởi thầy thuốc người Thụy Sĩ Friedrich Miescher, người mà vào năm 1869, đã khám phá ra một chất vi mô trong mủ của băng gạc được tháo bỏ sau phẫu thuật. Vì nó nằm trong nhân của tế bào, ông đã gọi nó là "nuclein". Năm 1878, Albrecht Kossel đã cô lập được thành phần không phải là protein của "nuclein", acid nucleic, và sau đó ông cô lập được năm nucleobase cơ bản của nó. Năm 1919, Phoebus Levene nhận biết được các đơn vị của nucleotide là base, đường và phosphat. Levene đề xuất rằng DNA chứa một chuỗi các đơn vị nucleotide được liên kết với nhau bằng các nhóm phosphat. Levene đã nghĩ rằng mạch này là ngắn và các base lặp lại theo một thứ tự cố định. Năm 1937, William Astbury chụp được ảnh thành phần nhiễu xạ tia X đầu tiên cho thấy DNA có một cấu trúc đều đặn.
Năm 1927, Nikolai Koltsov đề xuất rằng các tính trạng di truyền có thể được thừa hưởng thông qua một "phân tử di truyền khổng lồ" cấu thành từ "hai mạch đối xứng mà có thể sao chép theo cách bán bảo tồn sử dụng từng mạch như là một khuôn mẫu". Năm 1928, Frederick Griffith trong thí nghiệm của ông đã khám phá ra các tính trạng dạng "trơn" của phế cầu khuẩn (Pneumococcus) có thể truyền sang dạng "thô" của cùng một loài vi khuẩn bằng cách trộn các vi khuẩn dạng "trơn" đã bị giết với các vi khuẩn dạng "thô" còn sống bằng thí nghiệm nổi tiếng gọi là thí nghiệm Griffith. Hệ thống thí nghiệm này cung cấp gợi ý rõ ràng đầu tiên về DNA mang thông tin di truyền—theo thí nghiệm Avery–MacLeod–McCarty—khi Oswald Avery, cùng với các đồng nghiệp Colin MacLeod và Maclyn McCarty, nhận ra DNA tuân theo nguyên lý biến nạp trong thí nghiệm Griffith vào năm 1943. Vai trò của DNA trong di truyền được xác nhận vào năm 1952, khi Alfred Hershey và Martha Chase trong thí nghiệm Hershey–Chase chỉ ra rằng DNA là vật liệu di truyền của thực khuẩn thể T2.
Năm 1953, James Watson và Francis Crick lần đầu tiên đề xuất mô hình mà được chấp nhận ngày nay với cấu trúc DNA chuỗi xoắn kép đăng trên tạp chí Nature. Mô hình phân tử chuỗi xoắn kép DNA của họ khi ấy dựa trên ảnh chụp nhiễu xạ tia X (còn gọi là "Ảnh chụp 51") do Rosalind Franklin và Raymond Gosling thực hiện vào tháng 5 năm 1952, và dựa trên thông tin rằng các base DNA ghép cặp với nhau.
Chứng cứ thực nghiệm ủng hộ mô hình Watson và Crick được công bố trong một loạt 5 bài báo đăng trên cùng một số của tờ Nature. Trong các bài báo này, bài viết của Franklin và Gosling là công trình đầu tiên của chính họ công bố dữ liệu về nhiễu xạ tia X và phương pháp phân tích gốc giúp ủng hộ một phần mô hình của Watson và Crick; trong số báo này cũng bao gồm bài viết về cấu trúc DNA của Maurice Wilkins với hai đồng nghiệp của ông, khi họ thực hiện phân tích ảnh chụp tia X của dạng B-DNA trong cơ thể sống (in vivo) mà cũng ủng hộ cho sự có mặt trong cơ thể sống của cấu trúc chuỗi xoắn kép DNA như đề xuất của Crick và Watson về mô hình phân tử DNA của họ trong bài báo dài 2 trang đăng ở số trước của tạp chí Nature. Năm 1962, khi ấy Franklin đã qua đời, Watson, Crick, và Wilkins cùng nhận Giải Nobel Sinh lý và Y học. Do điều lệ của Quỹ Nobel chỉ trao giải cho những nhà khoa học còn sống. Vẫn có những tranh luận về sau liên quan đến những ai xứng đáng được công nhận liên quan đến khám phá này.
Trong một buổi nói chuyện có tầm ảnh hưởng vào năm 1957, Crick đưa ra luận thuyết trung tâm của sinh học phân tử, báo hiệu trước về mối quan hệ giữa các phân tử DNA, RNA, và protein, và khớp nối với "giả thuyết về dòng thông tin". Chứng cứ thực nghiệm cuối cùng xác nhận cơ chế sao chép mà hàm ý cấu trúc chuỗi xoắn kép được công bố vào năm 1958 thông qua thí nghiệm Meselson–Stahl. Những công trình về sau của Crick và các đồng nghiệp cũng như của nhiều nhà khoa học khác chứng tỏ mã di truyền có cơ sở là tổ hợp của bộ ba base không chồng lợp nhau, hay còn gọi là các codon, cho phép Har Gobind Khorana, Robert W. Holley và Marshall Warren Nirenberg làm sáng tỏ mã di truyền. Những phát hiện này đã khai sinh ra ngành sinh học phân tử.
Xem thêm
- Nhiễm sắc thể thường
- Tinh thể học
- Thư viện hóa học DNA mã hóa
- Giải trình tự DNA
- Đại phân tử
- Rối loạn di truyền
- Haplotype
- DNA microarray
- Bệnh di truyền
- Bản so sánh những phần mềm mô phỏng acid nucleic
- Giảm phân
- Chuỗi xoắn kép acid nucleic
- Ký hiệu acid nucleic
- Trình tự acid nucleic
- Thuyết pangen
- Phosphoramidit
- Thẩm tách Southern
- Kỹ thuật tán xạ tia X
- Acid nucleic xeno
- RNA
- Deoxyribozyme
Tham khảo
- Berry, Andrew; Watson, James. (2003). DNA: the secret of life. New York: Alfred A. Knopf. ISBN 0-375-41546-7.Quản lý CS1: nhiều tên: danh sách tác giả (liên kết)
- Calladine, Chris R.; Drew, Horace R.; Luisi, Ben F.; Travers, Andrew A. (2003). Understanding DNA: the molecule & how it works. Amsterdam: Elsevier Academic Press. doi:10.1016/0307-4412(94)90110-4. ISBN 0-12-155089-3.
- Dennis, Carina; Julie Clayton (2003). 50 years of DNA. Basingstoke: Palgrave Macmillan. doi:10.1007/978-1-137-11781-6. ISBN 1-4039-1479-6. Bản gốc lưu trữ ngày 4 tháng 7 năm 2021. Truy cập ngày 11 tháng 12 năm 2016.
- Judson, Horace F. 1979. The Eighth Day of Creation: Makers of the Revolution in Biology. Touchstone Books, ISBN 0-671-22540-5. 2nd edition: Cold Spring Harbor Laboratory Press, 1996 paperback: ISBN 0-87969-478-5. doi:10.1086/383894
- Olby, Robert C. (1994). The path to the double helix: the discovery of DNA (PDF). New York: Dover Publications. ISBN 0-486-68117-3. Bản gốc (PDF) lưu trữ ngày 20 tháng 12 năm 2016. Truy cập ngày 11 tháng 12 năm 2016., first published in October 1974 by MacMillan, with foreword by Francis Crick; the definitive DNA textbook, revised in 1994 with a 9-page postscript
- Micklas, David. 2003. DNA Science: A First Course. Cold Spring Harbor Press: ISBN 978-0-87969-636-8
- Ridley, Matt (2006). Francis Crick: discoverer of the genetic code. Ashland, OH: Eminent Lives, Atlas Books. doi:10.1056/NEJMbkrev56783. ISBN 0-06-082333-X. Bản gốc lưu trữ ngày 4 tháng 7 năm 2021. Truy cập ngày 11 tháng 12 năm 2016.
- Olby, Robert C. (2009). Francis Crick: A Biography. Plainview, N.Y: Cold Spring Harbor Laboratory Press. doi:10.1002/bmb.20462. ISBN 0-87969-798-9.
- Rosenfeld, Israel. 2010. DNA: A Graphic Guide to the Molecule that Shook the World. Columbia University Press: ISBN 978-0-231-14271-7
- Schultz, Mark and Zander Cannon. 2009. The Stuff of Life: A Graphic Guide to Genetics and DNA. Hill and Wang: ISBN 0-8090-8947-5
- Stent, Gunther Siegmund; Watson, James. (1980). The Double Helix: A Personal Account of the Discovery of the Structure of DNA. New York: Norton. doi:10.1021/ed045p623.2. ISBN 0-393-95075-1. Bản gốc lưu trữ ngày 11 tháng 5 năm 2019. Truy cập ngày 11 tháng 12 năm 2016.Quản lý CS1: nhiều tên: danh sách tác giả (liên kết)
- Watson, James. 2004. DNA: The Secret of Life. Random House: ISBN 978-0-09-945184-6
- Wilkins, Maurice (2003). The third man of the double helix the autobiography of Maurice Wilkins. Cambridge, Eng: University Press. ISBN 0-19-860665-6.
Liên kết ngoài
| Wikiquote Anh ngữ sưu tập danh ngôn về: |
| Wikimedia Commons có thêm hình ảnh và phương tiện truyền tải về DNA. |
- DNA tại Từ điển bách khoa Việt Nam
- DNA tại Encyclopædia Britannica (tiếng Anh)
- DNA trên DMOZ
- DNA binding site prediction on protein Lưu trữ 2007-03-06 tại Wayback Machine
- DNA the Double Helix Game Lưu trữ 2016-11-21 tại Wayback Machine From the official Nobel Prize web site
- DNA under electron microscope Lưu trữ 2007-06-23 tại Wayback Machine
- Dolan DNA Learning Center Lưu trữ 2016-10-30 tại Wayback Machine
- Double Helix: 50 years of DNA Lưu trữ 2015-04-05 tại Wayback Machine, Nature
- Proteopedia DNA Lưu trữ 2016-11-09 tại Wayback Machine
- Proteopedia Forms of DNA Lưu trữ 2016-11-09 tại Wayback Machine
- ENCODE threads explorer Lưu trữ 2019-01-06 tại Wayback Machine ENCODE home page. Nature (journal)
- Double Helix 1953–2003 National Centre for Biotechnology Education
- DNA from the Beginning Study Guide Lưu trữ 2016-04-06 tại Wayback Machine Genetic Education Modules for Teachers
- PDB Molecule of the Month DNA Lưu trữ 2016-12-03 tại Wayback Machine
- Olby R (2003). “Quiet debut for the double helix” (PDF). Nature. 421 (6921): 402–5. doi:10.1038/nature01397. PMID 12540907. Bản gốc (PDF) lưu trữ ngày 16 tháng 6 năm 2010. Truy cập ngày 13 tháng 11 năm 2016.
- Ellen Moody's Teaching Lưu trữ 2010-06-16 tại Wayback Machine Rosalind Franklin's contributions to the study of DNA
- The Register of Francis Crick Personal Papers 1938 - 2007 Lưu trữ 2007-08-25 tại Wayback Machine tại Mandeville Special Collections Library, Geisel Library, Đại học California, San Diego
- U.S. National DNA Day Lưu trữ 2016-12-01 tại Wayback Machine—watch videos and participate in real-time chat with top scientists
- “Clue to chemistry of heredity found” (PDF). The New York Times. ngày 13 tháng 6 năm 1953. Bản gốc (PDF) lưu trữ ngày 26 tháng 8 năm 2012. Truy cập ngày 9 tháng 4 năm 2010. Tờ báo Mỹ đầu tiên đưa tin về việc phát hiện ra cấu trúc DNA.
- Seven-page, handwritten letter that Crick sent to his 12-year-old son Michael in 1953 describing the structure of DNA. Lưu trữ 2015-07-18 tại Wayback Machine Xem Crick’s medal goes under the hammer Lưu trữ 2016-04-02 tại Wayback Machine, Nature, 5 tháng 4 năm 2013.
- 3D map of DNA reveals hidden loops that allow genes to work together Lưu trữ 2016-11-09 tại Wayback Machine (11 tháng 12 năm 2014), Science (Daily News)
|
Chủng loại Acid nucleic
| |||||||
|---|---|---|---|---|---|---|---|
| Thành phần hợp thành |
|
 |
|||||
|
Acid ribonucleic |
|
||||||
| Acid deoxyribonucleic | |||||||
| Chất tương tự | |||||||
| Vectơ tách dòng | |||||||
| Giới thiệu về di truyền học |
 |
||||||
|---|---|---|---|---|---|---|---|
| Phiên mã |
|
||||||
| Dịch mã |
|
||||||
| Biểu hiện gen | |||||||
| Người có tầm ảnh hưởng |
|||||||
| Thành phần then chốt | |
|---|---|
| Chủ đề chính | |
| Khảo cổ học di truyền | |
| Chủ đề liên quan | |
| Tổng quan |
|
 
|
||||||
|---|---|---|---|---|---|---|---|---|
| Kỹ thuật |
|
|||||||